Kubernetes
This section covers different strategies for deploying Dagger on a Kubernetes cluster. Its primary focus are teams that looking forward to self-host their CI infrastructure and use Dagger at its core to run their pipelines.
Running Dagger in Kubernetes is generally a good choice for:
- Teams with demanding CI/CD performance needs or regulated environments.
- Individuals or teams that want to self-host their CI infrastructure.
- Better integration with internal existing infrastructure.
- Mitigate CI vendor lock-in
How it works
Architecture patterns
This section describe a few common architecture patterns to consider when setting up a Continuous Integration (CI) environment using Dagger on Kubernetes.
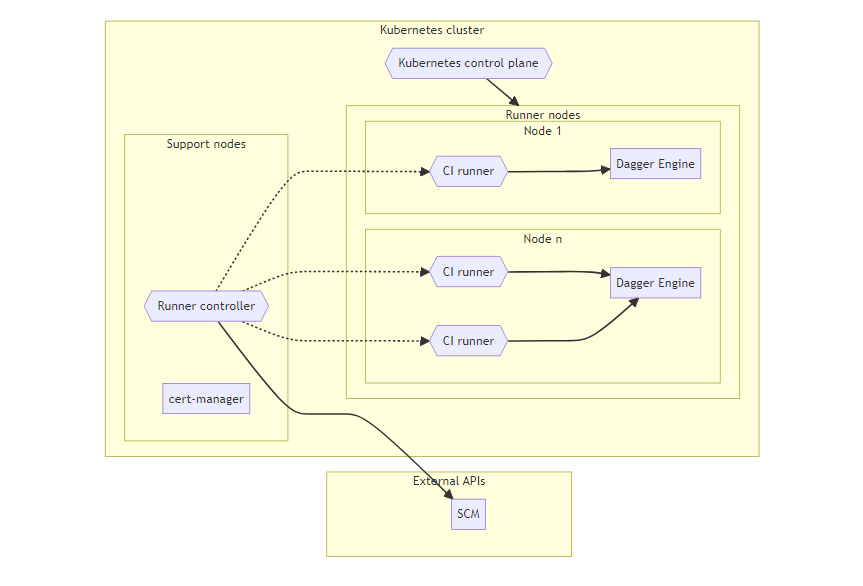
Persistent nodes
The base pattern consists of persistent Kubernetes nodes with ephemeral CI runners.
The minimum required components are:
- Kubernetes cluster, consisting of support nodes and runner nodes.
- Runner nodes host CI runners and Dagger Engines.
- Support nodes host support and management tools, such as certificate management, runner controller & other functions.
- Certificates manager, required by Runner controller for Admission Webhook.
- Runner controller, responsible for managing CI runners in response to CI job requests.
- CI runners are the workhorses of a CI/CD system. They execute the jobs that are defined in the CI/CD pipeline.
- Dagger Engine on each runner node, running alongside one or more CI runners.
- Responsible for running Dagger pipelines and caching intermediate and final build artifacts.
In this architecture:
- Kubernetes nodes are persistent.
- CI runners are ephemeral.
- Each CI runner has access only to the cache of the local Dagger Engine.
- The Dagger Engine is deployed as a DaemonSet, to use resources in the most efficient manner and enable reuse of the local Dagger Engine cache to the greatest extent possible.
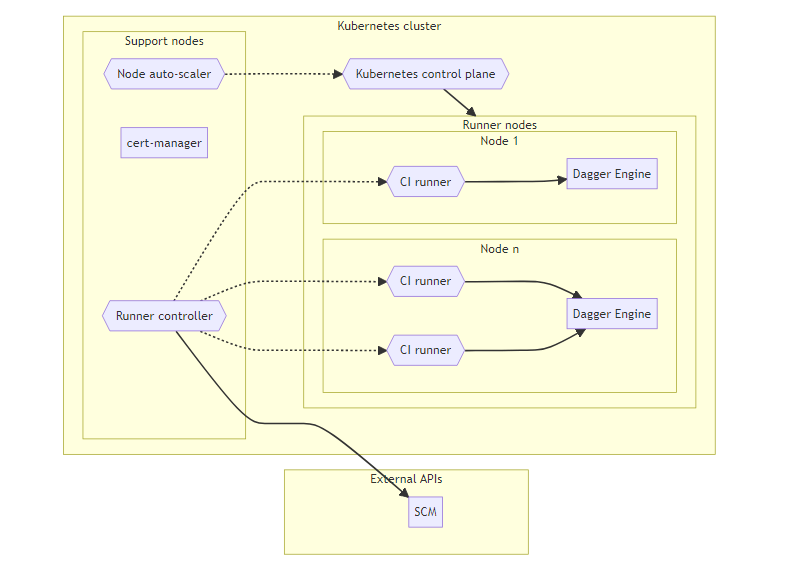
Ephemeral, auto-scaled nodes
The base architecture pattern described previously can be optimized by the addition of a node auto-scaler. This can automatically adjust the size of node groups based on the current workload. If there are a lot of CI jobs running, the auto-scaler can automatically add more runner nodes to the cluster to handle the increased workload. Conversely, if there are few jobs running, it can remove unnecessary runner nodes.
This optimization reduces the total compute cost since runner nodes are added & removed based on the number of concurrent CI jobs. The trade-off is that we lose all Dagger Engine state stored on the runner node that is de-provisioned. Configuring persistent volumes is worth considering if the platform supports it.
In this architecture:
- Kubernetes nodes provisioned on-demand start with a "clean" Dagger Engine containing no cached data.
- Cached build artifacts from previous runs will be lost when the runner node gets de-provisioned (can be mitigated via persistent volumes).
Recommendations
When deploying Dagger on a Kubernetes cluster, it's important to understand the design constraints you're operating under, so you can optimize your configuration to suit your workload requirements. Here are two key recommendations.
Runner nodes with moderate to large NVMe drives
The Dagger Engine cache is used to store intermediate build artifacts, which can significantly speed up your CI jobs. However, this cache can grow very large over time. By choosing nodes with large NVMe drives, you ensure that there is plenty of space for this cache. NVMe drives are also much faster than traditional SSDs, which can further improve performance. These types of drives are usually ephemeral to the node and much less expensive relative to EBS-type volumes.
Runner nodes appropriately sized for your workloads
Although this will obviously vary based on workloads, a minimum of 2 vCPUs and 8GB of RAM is a good place to start. One approach is to set up the CI runners with various sizes so that the Dagger Engine can consume resources from the runners on the same node if needed.
Prerequisites
- A running Kubernetes cluster with a pre-configured
kubectlprofile. - The Helm package manager installed on your local machine.
Example
Dagger provides a Helm chart to create a Dagger Engine DaemonSet on a Kubernetes cluster. A DaemonSet ensures that all matching nodes run an instance of Dagger Engine.
The following command uses the Dagger Helm chart to create a Dagger Engine DaemonSet on the cluster:
helm upgrade --install --namespace=dagger --create-namespace \
dagger oci://registry.dagger.io/dagger-helm
This Dagger Engine DaemonSet configuration is designed to:
- best utilize local Non-Volatile Memory Express (NVMe) hard drives of the worker nodes
- reduce the amount of network latency and bandwidth requirements
- simplify routing of Dagger SDK and CLI requests
Wait for the Dagger Engine to become ready:
kubectl wait --for condition=Ready --timeout=60s pod \
--selector=name=dagger-dagger-helm-engine --namespace=dagger
Find more information on what was deployed using the following command:
kubectl describe daemonset/dagger-dagger-helm-engine --namespace=dagger
Get a Dagger Engine pod name:
DAGGER_ENGINE_POD_NAME="$(kubectl get pod \
--selector=name=dagger-dagger-helm-engine --namespace=dagger \
--output=jsonpath='{.items[0].metadata.name}')"
export DAGGER_ENGINE_POD_NAME
Next, set the _EXPERIMENTAL_DAGGER_RUNNER_HOST variable so that the Dagger CLI knows to connect to the Dagger Engine that you deployed as a Kubernetes pod:
_EXPERIMENTAL_DAGGER_RUNNER_HOST="kube-pod://$DAGGER_ENGINE_POD_NAME?namespace=dagger"
export _EXPERIMENTAL_DAGGER_RUNNER_HOST
Finally, run an operation that shows the kernel info of the Kubernetes node where this Dagger Engine runs:
dagger query <<EOF
{
container {
from(address:"alpine") {
withExec(args: ["uname", "-a"]) { stdout }
}
}
}
EOF
Resources
Below are some resources from the Dagger community that may help as well. If you have any questions about additional ways to use Kubernetes with Dagger, join our Discord and ask your questions in our Kubernetes channel.
- Kubernetes Dagger modules.
- Video: Kubernetes in Dagger by Marcos Lilljedahl: In this demo, Marcos explains how to run Kubernetes clusters using Dagger. He addresses the challenges and solutions in integrating Kubernetes within Dagger and shares a practical setup using the k3s Dagger Module
- Video: Kubernetes Infinity Stones: Can Dagger Complete My Set? by Diego Ciangottini: In this demo, Diego explores the integration of Dagger with Kubernetes to enhance the deployment and management of components across different environments.
- Video: Dagger and Kubernetes Repo Example by Batuhan Apaydın and Koray Oksay: In this demo, Batuhan and Koray demonstrate how to use Dagger in a Kubernetes environment to manage the deployment of applications. They use a simple Go application that exposes a REST API. The application is deployed in a Kubernetes cluster using Dagger with a pipeline-as-code approach.
- Video: Argo Workflows with Dagger Functions
- Blog post: On-Demand Dagger Engines with Argo CD, EKS, and Karpenter
About Kubernetes
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It was originally designed by Google and is now maintained by the Cloud Native Computing Foundation.